03. 기계학습(머신러닝) 기초2
1) 기본 Package 설정
앞으로 공부하면서 사용할 Package들을 절차에 맞춰 미리 소개하겠다.
필요에 따라 각각의 속도에 맞춰 pacakge를 새롭게 설치해도 되지만,
그냥 공부가 목적이라면 하나의 file로 만들어 가장 앞쪽에 미리 적어 놓는 것이 더욱 효율 적일 것이다.
참고로 나는 이미 사용할 모델과 data가 있어서 모든 package가 필요하지는 않기에 나에게 필요하지 않은 package들과 추 후에 사용할 모델에 대해서 주석처리해두었다.
# 기본
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt # 그래프
# # 데이터 가져오기
# from sklearn import datasets # sklearn에 있는 data import
# # 데이터 전처리
# from sklearn.preprocessing import StandardScaler # 연속 변수 표준화
# from sklearn.preprocessing import LabelEncoder # 범주형 변수 수치화
# 훈련/검증용 데이터 분리
from sklearn.model_selection import train_test_split # 훈련과 테스트를 위한 데이터 분리
# # 분류 모델
# from sklearn.naive_bayes import GaussianNB # 나이브 베이즈 분류
# from sklearn.tree import DecisionTreeClassifier # 의사결정나무
# from sklearn.ensemble import RandomForestClassifier # 랜덤 포레스트
# from sklearn.ensemble import BaggingClassifier # 앙상블
# from sklearn.linear_model import LogisticRegression # 로지스틱 회귀분석
# from sklearn.svm import SVC # SVM(서포트벡터머신)
# from sklearn.neural_network import MLPClassifier # 다층 인공신경망
# 모델 검정
from sklearn.metrics import confusion_matrix, classification_report # 정오분류표
from sklearn.metrics import accuracy_score, precision_score, recall_score, f1_score, make_scorer # 정확도, 민감도 등
from sklearn.metrics import roc_curve # ROC 곡선
# # 최적화
# from sklearn.model_selection import cross_validate # 교차 타당도
# from sklearn.pipeline import make_pipeline # 파이프라인 구축
# from sklearn.model_selection import learning_curve, validation_curve # 학습곡선, 검증곡선
# from sklearn.model_selection import GridSearchCV # 하이퍼파라미터 튜닝2) 데이터 가져오기
데이터를 불러오는 방법에는 2가지가 있다.
- Python에 있는 data를 불러오는 방법
- 자신의 기존 data를 불러오는 방법
먼저, 사이킷런의 기본 dataset을 불러오는 방법은 다음과 같다.
from sklearn import datasets # sklearn에 있는 data importiris = datasets.load_iris()
iris.keys()# Data와 Target으로 구분
# Python은 예측변수와 결과변수로 구분해서 분석
X = iris.data[:, [2,3]]
y = iris.target자신이 가지고 있던 기존의 원본데이터(csv)파일을 dataframe 형태로 가져올 때는,
이전 part에서 배웠던 pandas를 사용해 불러올 수 있다.
employee_data = pd.read_csv('../Data/train.csv')
employee_data.head()원본 데이터를 pandas의 dataframe으로 가져온 후,
필요한 데이터만 추출해, Data와 target으로 구분하면 된다.
3) 데이터 전처리
만약, 분석하고자 하는 data가 모두 숫자형 literal이라면 상관없겠지만,
대부분 분석하고자 하는 data에는 문자형 literal도 섞여 있을 가능성이 많다.
범주형 자료를 숫자로 변환하기 위해서는 우선 해당 변수가 순서형 변수인지, 아닌지 확인해야 한다.
순서형 변수는 초등학교 > 중학교 > 고등학교와 같이 각각의 변수들 사이에 정확한 개연성이 있는 것들을 의미하며, 이 경우 그냥 순서에 따라 값을 메겨주면 된다.
순서형 변수가 아니라면 OneHotEncoder를 활용해 전처리하는 것이 일반적이다.
데이터 정규화(표준화)
분류 방법에 따라 표준화를 시키는 모델과 시키지 않는 모델로 나뉜다.
- 원본 데이터를 그대로 유지하는 방법 : 의사결정나무, 랜덤 포레스트, 나이브 베이즈 분류
- 표준화 후 분석하는 방법 : 로지스틱 회귀 분석, 회귀 분석, 인공신경망
뿐만 아니라 군집 분석도 정규화가 필요하다.
군집 분석 시 표준화를 하지 않으면 단위에 따라 영향을 받을 수 있으므로 주의해야 한다.
불균형한 클래스
희소 사건에 대한 오버 샘플링의 경우 이를 처리할 수 있어야 한다.
- 언더샘플링 : 작은 쪽 데이터에 맞춤
- 오버샘플링 : 큰 쪽 데이터에 맞춤
- SMOTE(Synthetic Minority Oversampling Technigue)
- 가장 대중적으로 사용하는 방법으로, 작은 쪽 샘플과 유사한 샘플을 찾아서 추가하는 것이다.
4) 훈련/검증용 데이터 분할
실제 데이터를 다룰 때에는 범주형 변수와 연속 변수가 혼합되어 있는 경우가 대부분이다.
이러한 경우에는 훈련/테스트 셋을 나눈 후에 전처리를 하기 보다는, 전처리 작업 후에 훈련/검증용 셋을 구분하는 것이 좋다.
Training, Test set 분류
Python에서 훈련 및 검증용 세트로 데이터를 구분하는 방법은 다음과 같다.
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = \
train_test_split(X, y,
test_size = 0.3, # test set의 비율
random_state = 1, # 무작위 시드 번호
stratify = y) # 결과 레이블의 비율대로 분리5) 모델 구축
먼저는 모델을 훈련시킨다.
어떠한 모델로 훈련시키느냐에 따라 분석 방법이 달라지는 것이며, 이 과정 자체가 바뀌는 것은 아니다.
6) 모델 검정
# 훈련된 모델을 이용해 test date 검정 (예시)
y_pred = svm.predict(X_test)
# 정오분류표 (confuxion matrix)
# python의 정오분류표에서는 column에 예측값이 들어간다.
import pandas as pd
confmat = pd.DataFrame(confusion_matrix(y_test, y_pred),
index=['True[0]', 'True[1]', 'True[2]'],
columns = ['Predict[0]', 'Predict[1]', 'Predict[2]'])
confmat
# 정확도, 정밀도, 재현율 등
print(f'잘못 분류된 sample 갯수 : {(y_test != y_pred).sum()}')
print(f'정확도 : {accuracy_score(y_test, y_pred):.2f}%')
print(f'정밀도 : {precision_score(y_true=y_test, y_pred=y_pred):.3f}%')
print(f'재현율 : {recall_score(y_true=y_test, y_pred=y_pred):.3f}%')
print(f'F1 : {f1_score(y_true=y_test, y_pred=y_pred):.3f}%')model 검정에서 가장 많이 쓰이는 방식은 ROC를 이용하는 것이다.
보통, 1 - 특이도 로 계산하기 때문에 민감도(TPR)이 높고 1 - 특이도(FPR)은 낮을 수록 좋은 모델이라고 볼 수 있다.

또한 Pipeline을 이용하는 방법도 자주 사용한다.
여러 개의 변환 단계를 거쳐야 할 경우, pipeline을 사용해 연속해서 필요한 기능들을 자동적으로 수행하도록 만드는 방법이다.
7) 최적화
교차 검정 (Cross Validation)
모델의 성능을 검증하기 위한 방법으로, 홀드아웃 교차검정과, K-fold 교차검정이 있다.
홀드아웃 교차검정의 경우, 기존의 방식과 같이 training set와 test set을 처음부터 분류해놓고 검정하는 방법이다.
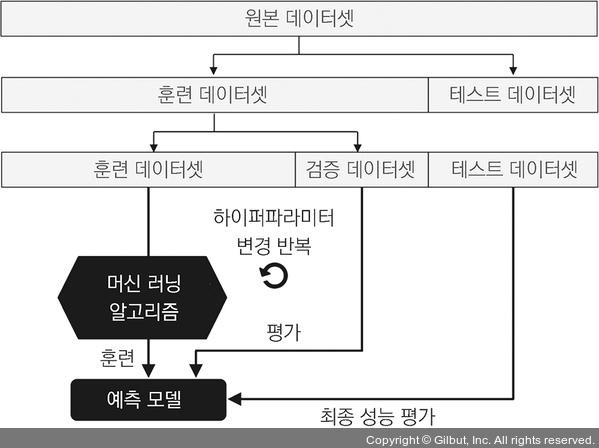
K-fold 교차검정은 각각의 set을 K개로 분할하여 test set으로 사용하는 방법이다.
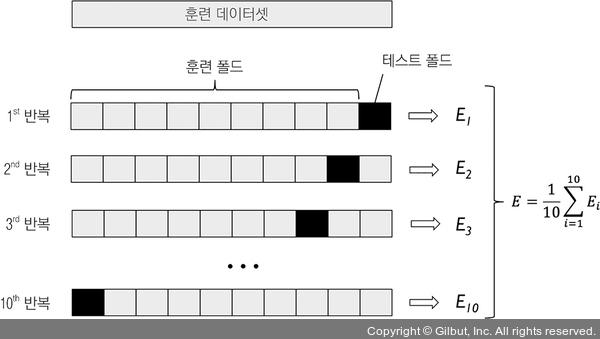
Python은 정확도에 따라 편향과 분산을 비교한다.
training set과 test set이 모두 정확도를 기준으로 최적화를 진행하게 된다.
검증 곡선의 값의 변화를 확인해 계속해서 하이퍼 파라미터를 튜닝하게 되는 것이다.
이에 관련된 내용은 중요하기도 하고, 다뤄야 할 내용이 많기때문에 추후에 다시 설명하도록 하겠다.
'Study > AI' 카테고리의 다른 글
| 04. 데이터 분석 절차 (0) | 2022.02.07 |
|---|---|
| 02. 기계학습(머신러닝) 기초1 (0) | 2022.02.05 |
| 01. 데이터 처리 (Numpy, Pandas 기초) (0) | 2022.02.05 |
| M1 Mac(Apple Silicon)에서 머신러닝 개발환경 구축하기 (0) | 2022.01.29 |
| 머신러닝 공부에 유용한 사이트 및 유튜브 추천 (0) | 2022.01.27 |

댓글